
버티의 블로그
[자연어처리 #06] BERT and GPT 본문
이번에 배울 모델을 Transformer의 구조를 활용한 대표적인 사전훈련모델 2가지인 BERT와 GPT를 알아볼 것이다.
BERT
BERT는 Transformer의 encoder를 활용한 사전 훈련 언어 모델로, 다음과 같은 특징이 있다.
- 양방향성(Bidirectional) Language Model이다.
- 대용량 corpus data로 모델을 학습시킨 후, task에 맞게 전이학습(transfer learning)을 하는 모델이다.
기존의 word embedding 방법인 Word2Vec, GloVe, FastText와 같은 방법들은 이후 task를 위해 LSTM이나 Seq2seq같은 복잡한 구조를 사용해야만 했지만, BERT를 사용하면 이러한 구조 없이 단순한 Nerual Network만 BERT에 얹어서 task를 진행해도 성능이 잘 나온다는 장점이 있다.
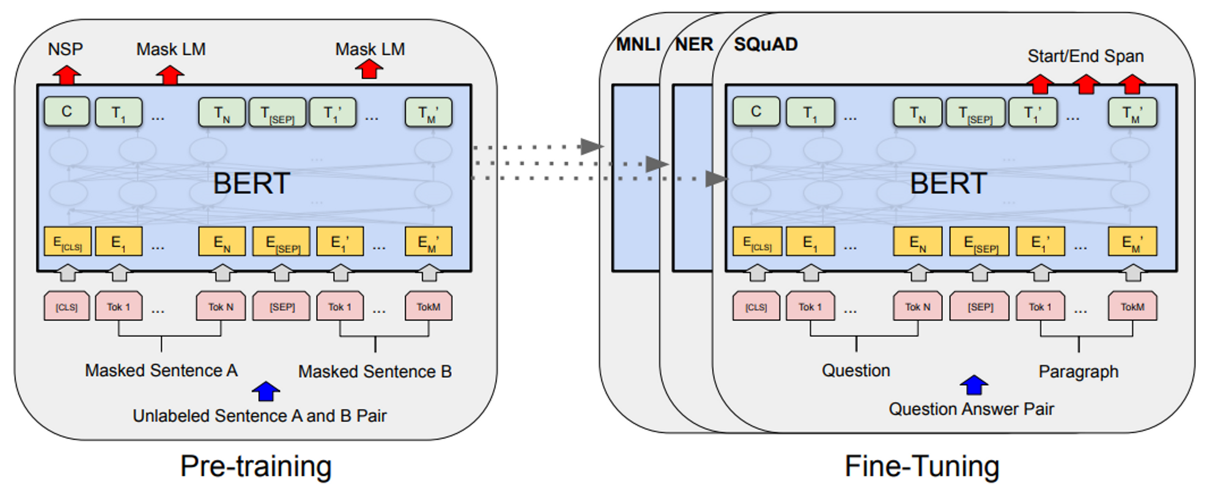
BERT는 왼쪽 그림처럼 대용량 corpus에서 pre-training을 한 다음 weight를 가져와서 오른쪽 그림처럼 task에 알맞게 fine-tuning을 한다.
1) Pre-Training
BERT의 입력에는 임베딩된 문장 A, B를 한번에 입력해주고, encoder를 거쳐 NSP와 Mask LM(MLM) 결과값을 출력하는데, 이 둘이 BERT에서 사전훈련하는 대상(목표)이다.

- Mask Language Model (MLM) : 입력 단어의 15%를 masking하여 학습한다.
- masking한 15% 중 80%는 일반 masking, 10%는 랜덤한 단어로 치환, 10%는 그대로 둔다.
- 이제 masking한 단어를 예측하도록 neural network에 요구한다.
- Transformer Encoder에서 self-attention으로 masking한 단어를 예측한다.
- 그럼 mask된 단어가 query(목표), 나머지 단어가 key/value라고 생각하면 된다.
- 이때 BERT는 양방향성이므로 masking된 단어 양쪽으로 참조가 가능하다.

- Next Sentence Prediction (NSP) : 문장 A와 B가 서로 이어져도 어색하지 않은지 확인, 이어지면 1 아니면 0을 출력
즉, 단어 단위로 학습하는 것이 MLM, 문장 단위로 학습하는 것이 NSP이다.

위 그림은 BERT의 input인데, 문장이 총 3가지의 임베딩 레이어를 거치고 이들의 합을 Embedding Input으로 사용한다.
- Token Embedding : 단어 단위로 토큰화
- Segment Embedding : 문장 단위로 토큰화
- Position Embedding : Transformer와 동일한 Position Embedding
2) Fine-Tuning

위 그림은 두 문장이 pair인지 확인하는 task에서 BERT를 이용한 fine-tuning한 예시이다. 이렇게 임베딩을 거친 문장들이 BERT에 들어가고 Transformer로 학습시킨다. 그럼 마지막 Layer에 transfer learning을 해서 fine-tuning시키고 나온 class label을 task의 결과로 사용한다. 이 밖에도 아래와 같이 여러 예시들이 존재한다.

- (a) : 문장 하나를 입력받고 label 토큰이 분류값 중 하나가 되도록 학습
- (b) : 두 시퀀스가 들어오면 후반부의 시작 토큰부터 질문의 답을 생성
- (c) : 각 문장의 요소 별로 품사를 태깅
GPT

GPT는 BERT와 다르게 단방향성으로 무조건 앞에서 부터 순차적으로 계산한다. 따라서 Transformer의 decoder 구조의 masked self-attention 구조를 이용하여 뒷부분을 masking하여 self-attention을 한다.

위처럼 GPT는 공통적으로 12개의 Transformer의 decoder를 사용하고 task별로 약간씩 다른 fine-tuning 구조를 가진다. BERT처럼 corpus로 unsupervised pre-training을 진행한 후 task에 따른 supervised fine-tuning을 하는 것은 동일하다.
이제 BERT와 GPT 모두를 살펴보았는데, 각각의 특징을 활용한 적합한 task들은 다음과 같다.
- GPT : 문장 생성과 관련된 task
- BERT : 문장 의미 및 감정 분석 추출과 관련된 task
'AI > 자연어처리' 카테고리의 다른 글
| [자연어처리 #05] Attention & Transformer (0) | 2024.07.01 |
|---|---|
| [자연어처리 #04] Seq2Seq (0) | 2024.06.30 |
| [자연어처리 #03] RNN and LSTM (4) | 2024.06.30 |
| [자연어처리 #02] Text Mining (0) | 2024.06.23 |
| [자연어처리 #01] Text Preprocessing (0) | 2024.06.23 |



