
버티의 블로그
[강화학습 #02] Markov Decision Process 본문
728x90
Markov Decision Process
기존 MRP는 상태 전이가 확률적으로만 결정됐지만, MDP는 에이전트가 행동을 선택하는 것을 추가하여 이에 따른 상태 변화와 보상이 달라지는 환경을 뜻한다. MDP는 아래 4가지 요소로 구성된다.
- S : 에이전트의 상태
- A : 에이전트가 취할 수 있는 모든 가능한 action
- P : 특정 s에서 특정 a를 취했을 때 다음 s로 전이될 확률, P(s′∣s,a)가 이 의미이다.
- R : 특정 s에서 특정 a를 취했을 때 받는 보상, R(s,a,s′)로 표기한다.

V(s) 기준으로 설명하자면, 상태 s에서 특정

왼쪽 그림에서는 V(s)가 각 행동 a의 Q(s, a)와 a를 선택할 확률인

마찬가지로 벨만 방정식에서의 Q(s, a) 정의에서 V(s)를 벨만 방정식의 정의로 풀어쓰면 오른쪽 그림과 같다.

위 예시에서, 빨간색 원의 V(s)가 7.4가 나오게된 이유를 설명하자면 다음과 같다.
- 모든 state 전이 확률은 0.5, discount factor은 1로 가정.
- 우선 공부를 하면 가능한 state가 하나고, 리워드는 10이며, 해당 s의 V(s)는 0이다.
- 따라서 0.5 * (10 + 1 * (1 * 0)) = 5
- 술집을 가면 가능한 state가 3개이므로 세 경우를 모두 계산해준다.
- 리워드 : 1
- 첫번째 경우 : 0.2 * (-1.3) = - 0.26
- 두번째 경우 : 0.4 * 2.7 = 1.08
- 세번째 경우 : 0.4 * 7.4 = 2.96
- 따라서 0.5 * (1 + 1 * (- 0.26 + 1.08 + 2.96)) = 2.39
- 이 둘을 더하면 최종 V(s)가 된다. 5 + 2.39 = 7.39 -> 약 7.4

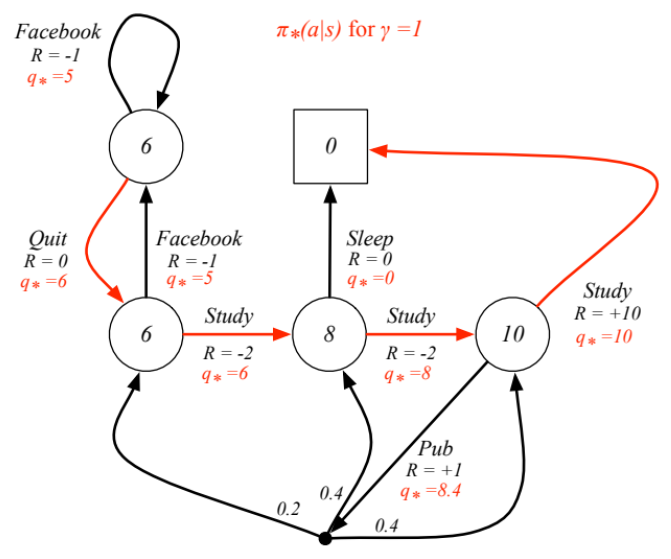
각 state에서 가능한 Q(s, a)중 가장 optimal(max)한 값을 q*로 정리하면 위와 같다. 이렇게 Bellman equation에 optimality를 적용해서 최적의 action을 선택할 수 있고 바로 Optimal policy를 구할 수 있게 된다. 이 식을 Bellman Optimal Equation이라 한다.

'AI > 강화학습' 카테고리의 다른 글
| [강화학습 #06] Model-Free Control (0) | 2024.06.04 |
|---|---|
| [강화학습 #05] λ-returns on TD (0) | 2024.05.20 |
| [강화학습 #04] Monte-Carlo and Temporal-Difference (0) | 2024.05.19 |
| [강화학습 #03] MDP Planning (0) | 2024.05.19 |
| [강화학습 #01] Reinforcement Learning Basic (0) | 2024.04.04 |
'AI/강화학습' Related Articles
more



